## Keysmash!
aslavb;lj aew aljvbError: <text>:2:11: unexpected symbol
1: ## Keysmash!
2: aslavb;lj aew
^
Welcome to the first R Training tutorial!
This tutorial is the first in a series covering fundamental skills in R. This first tutorial assumes no knowledge or previous experience of R or coding whatsoever, and is a great place to start if you’re totally brand new to R. Subsequent tutorials will build on the techniques and terminology introduced in each tutorial, so you’re strongly recommended to work through them in order.
Overall, these tutorials are designed to support faculty supervising undergraduate student dissertations in R at the University of Sussex, UK. The tutorials present a condensed guide through the key functions and statistical analyses that are covered in the first two years of core methods teaching.
In this series of tutorials we will learn the basics of R and how to write reproducible code. Computational reproducibility refers to the ability to get the same results each time you run the same analysis on the same dataset.
Studies have found that across research fields, only about a quarter to a third of published research papers are computationally reproducible (for examples see: Baker, 2016; Stodden et al., 2018; Crüwell et al., 2023).
This is bad.
Analyses using point-and-click software can be reproducible in theory, but (in our experience) that can take a long time to reproduce, the process is painful, and the opportunities for mistakes are everywhere. Completing your analyses in a code-based software like R is a step in the right direction, but it doesn’t automatically mean that a code-based analysis is reproducible. In this course, we will learn some of the common pitfalls that can make code not reproducible and help you pass Reny’s reproducibility certification with ease and flair.
To help build your reproducible-coding skills, look out for “RepRoducibility” boxes like the one below.
RepRoducibility: Tips and Tricks
This is a “RepRoducibility” box, which will highlight skills, techniques, or recommendations that will help make your code and analyses easier and smoother to reproduce.
Before we get started in R, just a couple notes for those using these materials.
This tutorial is designed to accompany a “Workbook” document. The workbook is a Quarto document with all of the headings and exercises from this tutorial, where you can take notes and try out the code in these tutorials.
If you are joining the live R Training at the University of Sussex, the workbooks are already available for you in projects for each week on the Posit Cloud workspace for this course. To access them, navigate to Posit Cloud and open the course workspace. If you haven’t joined the workspace yet, use the join link on the Posit Cloud page on Canvas.
In the workspace, you will see a list of projects available. These will have an “ASSIGNMENT” banner next to them. When you click on these projects, a new copy of the project will be generated for you to work in.
If you have found these materials from outside the R Training course, hello! Please work through and share these materials freely. If you would like to use the accompanying workbooks, you can download them on the Data and Workbooks page, but you will either need to set up your own Posit Cloud workspace or install R and RStudio on your own device.
You are now looking at the RStudio IDE itself. It is possible to use R directly with minimal interface, but using an integrated development environment like RStudio comes with a lot of additional convenience to make working with R smoother, easier, and more efficient.
It’s beyond the scope of this tutorial to cover all of the options and tools available in RStudio. Here we’ll focus only on the minimum to get started and build outward from there.
For a more complete tour, try this playlist of Andy Field’s RStudio tutorials.
Before anything else, open up the workbook for this tutorial. If you’re a little shaky on where this is, skip down to the screenshot below!
You should now be looking at a dashboard-like interface with four main windows, each with a bunch of tabs across the top, like pictured below. We’ll refer to each window by these names, which come from the most important or commonly used tab in each window.
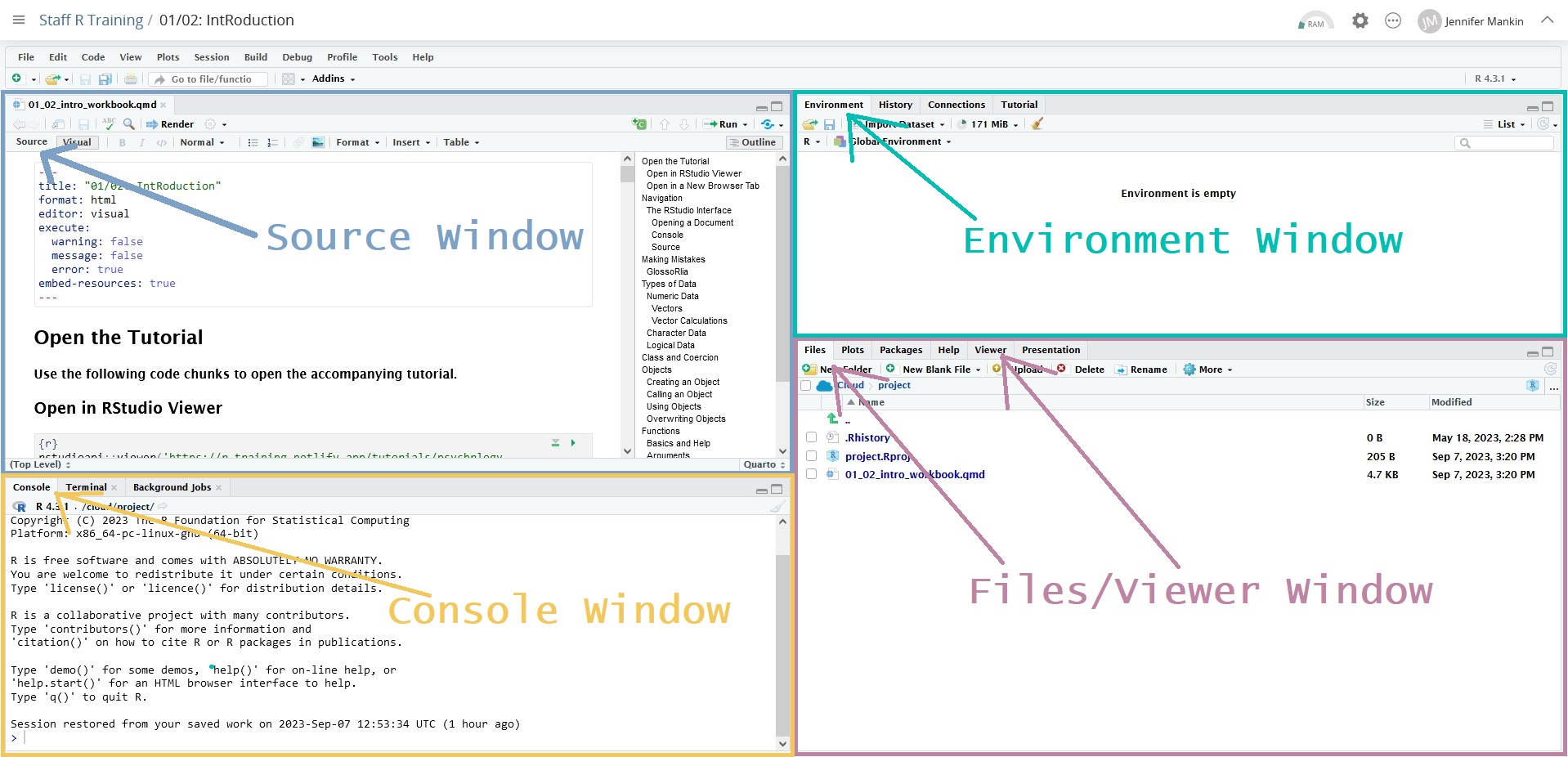
We will eventually work with all four of these windows, but if you’ve opened the workbook, you can ignore the Environment and Files windows for now. We’ll be focusing only on the other two: Source and Console.
The Source window is where any documents you want to create or work on will open up. What you have open now is a Quarto document, a type of document that integrates regular text and code. This document can be rendered, which means that all of the code is run and combined with the text to create a single output document. Quarto documents can be rendered into almost any format you like, including HTML webpages (like this one!), Word documents, PDFs, etc.
A Quarto document has three main elements: the YAML header, body text, and code chunks.

The YAML header controls the settings for rendering. The defaults are fine for our purposes, but see this guide for get started with using Quarto for more details.
You can use the text of a Quarto document more or less like you would a document in Word (or your word processor of choice). In the body of the document, you can write and format any text you want - notes, questions, thoughts, ideas, comments, etc. This workbook already contains all the headings from this tutorial to help you get organised, but please do delete or edit as you see fit.
The last element is the code chunk, which is where all R code should be written. Code chunks have a contrasting background colour, an {r} in the upper left corner, and two green buttons in the upper right. The one that looks like a green “play” button will run all the code in that chunk. Code chunks are like windows into R - little islands of code. Code chunks can only work with code, and will NOT handle any non-code text, unless it’s a comment (i.e. preceded by one or more #s.)
The {r} line in a code chunk is what defines that box as containing R code. You can write any code you like in the box underneath the {r}, but you must not write any code after the {r} on the same line or the code chunk box won’t work at all.
The Console is deceptively simple: just some stuff about the R version and acknowledgements, and the > symbol with a flashing cursor after it, waiting for you to type something. However, the Console is the heart of R, where anything you want to do actually happens. Every command that you type, anything you want R to do, goes through here.
So, already we have two places we could write R code: in a code chunk, or in the Console. How do we know where to start?
For the purposes of learning, by default, it’s best that you write all code into the workbook code chunks, so you have a detailed record of everything you’ve tried - even if it doesn’t work. Don’t delete code that produces errors! It’s useful as a record to understand what did and didn’t work as you expected, and it will be much easier to ask questions and get help with your code if you keep a copy of what you tried.
Outside of these sessions, whether to write a bit of R code in a code chunk in Quarto, or in the Console, largely depends on a single question: do you want to use this same line of code again in the future?
If yes, write the code in a code chunk. By adding the code to a document like Quarto, we are creating a record of all the steps we’ve taken in whatever task we are working on. Assuming we want to be able to use and refer to that code again in the future, it should go into a document.
If no, write the code in the Console. Code written directly in the Console isn’t saved or documented anywhere1. Some common uses of the Console are:
So, I often use the Console to test my code, building it up bit by bit, until it does what I want it to do. Then, when I’ve puzzled out the solution, I add it into a code chunk.
Imagine that working in R is like cooking, and writing a sequence of commands to, for example, clean a new dataset is like developing a new recipe.
If you’re developing a recipe, you likely wouldn’t just sit down and write down the final version if you’ve never tried the recipe before. Instead, you might experiment a bit with each step to see what works and what doesn’t.
Along the way, you may write notes to yourself: “Maybe try cumin?”, “Buy more kefir”, “2 tsp salt was too much!” Those notes are a part of the development process, relevant to what you’re doing now and helpful to try out or note down ideas, but they wouldn’t go in your final recipe. Those behind-the-scenes and under-development bits are the code you’d write in the Console.
When you find a technique or temperature or seasoning that works, you might add it as a step in your recipe. That final recipe, the steps that actually work the way you want, are the code in your code chunks.
If that seems like a lot to remember, don’t worry - we’ll practice both and let you know clearly if it should be one or the other.
Right, enough orientation - let’s get cracking!
Let’s begin with an affirmation:
You will, inevitably, make errors using R.
You will write commands that make sense to you that R doesn’t understand; and you will write commands that don’t make sense to you, that R does understand.
Errors are an essential and unavoidable part of learning R, so let’s start there.
Well, that went about as well as expected.
If you haven’t tried this yet, and your pristine document is just ominously staring at you, I’m serious - punch your keyboard if you have to, or let your cat walk on it, or play it as if it were a piano, and run it. There’s two important things to learn from this:
To ask R to do something, you must write commands out somewhere (in a code chunk, in the Console) and then run them.
Eventually, inevitably, something that you type WILL produce an error.
From our keysmashing above, you will have seen that aslavb;lj aew aljvb, Am I a coward? Who calls me villain?, and ¯\_(ツ)_/¯ are not valid commands in R. Although each of these has a communicative function for humans, R can’t understand them. In order to get the answer that we want, we have to ask R to do something in a way it can understand, by writing commands it can parse using the R language.
Very often, R communicates with you via errors. Unlike many other computer programmes you might be familiar with, an “error” in R doesn’t (usually!) mean a catastrophic failure and/or potential loss of hours of work2. Rather, whatever you’ve asked R to do, it’s essentially replied, “Sorry, I can’t do that.” Two of the most important skills you can develop early on with R is to treat errors as feedback, and to learn to read errors.
Treat errors as feedback: Errors aren’t (just) an annoyance, although running into lots of errors, usually just when you don’t want them the most!, can be incredibly frustrating. However, errors are just R’s way of telling you that it can’t do what you’ve asked it to do. If you’re trying to work out how to get R to do something, then the “no” of an error rules out whatever you’ve just tried. Rather than setting out to avoid errors, and thinking of an error as a “failure” to “do it right”, it’s much better to expect errors, and make use of them as part of the code-writing process.
Learn to read errors: Errors often contain useful information about what’s gone wrong and how to fix it. At minimum, errors usually contain the following information:
Errors vary wildly in understandability and helpfulness, from highly technical jargon to friendly and conversational with suggestions for fixing common problems. Even the obtuse ones, though, will become familiar with time.
One key concept for using R is the different ways it categorises data. “Data” here means any piece of information you put into R - a word, a number, the result of a command or calculation, a dataset, etc. Depending on the type of data you have, R will treat it differently, and some operations only work on certain types of data.
So, let’s have a look at how R encodes and deals with different types of data. Here we’ll cover three core data types - numeric, character, and logical - as well as a very common type for data analysis, namely factor. As we do so, we’ll practice some core skills in R.
The first, and perhaps most obvious, type of data in R is numbers. We’ll start by doing some calculations with common mathematical operators.
Remember that you can run all the code in a code chunk by pressing Ctrl/Cmd + Shift + Enter on your keyboard, or by clicking the green “play” arrow in the top right corner of the code chunk.
You can also run only a particular line of code, or something that you’ve highlighted, by pressing Ctrl/Cmd + Enter.
This might be what you’d expect. We’ve essentially asked R, “Give me 3958” (or whatever number you put in) and R obliges. The only thing that might be a surprise is the [1] marker, called an index. Basically, R has replied, “The first thing ([1]) that you asked me for is 3958.” We’ll come back to indices in a moment.
So, commas within numbers throw an error. This is because commas have an important role to play in the syntax of R, so long numbers must be inputted into R without any punctuation. However, full stops to mark decimal places are just fine.
Try for a moment switching to Source mode by clicking the Source button in the upper left hand of your Quarto document. You can see that RStudio helpfully marks out the part of the code that isn’t parsable (not in “grammatical” R) with a red ❌ next to the line number, and squiggly red underlining, likely familiar from word processing programmes, under the part of the code that’s causing the issue. It won’t do this for every error, but it’s very helpful for finding “grammatical” errors like extra or missing brackets or misplaced commas.
Next, let’s try doing some maths.
Important to note here is that we don’t need to type an = to get the answer, just the equation we want to solve and then run the code. Again, we’ve asked R, “Give me 40 + 8” (or whatever numbers you chose) and R replies with the answer.
You will not be surprised to learn that you can use R as a calculator to subtract, divide, and multiply as well.
This exercise also shows us something useful: you can run multiple commands within the same code chunk. While spaces are not meaningful to R (that is, 40 - 8 and 40-8 and 40 -8 are all read the same way), new lines have an important role to play separating out commands. Each command must have its own new line.
Let’s imagine I am running a study, and I want to generate some simple participant ID numbers to keep track of the order that they completed my study. I had 50 participants in total. I could do this by typing every number out one by one, but this is exactly the kind of tedious nonsense that R is great at. Instead, we’ll use the operator :, which means “every whole number between”.
Notice that the indices mentioned earlier have come up again. The first element after the [n] index is the nth element. Let’s have a look at this some more.
You may have tried something like this:
12:30 [1] 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 3023:55 [1] 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
[26] 48 49 50 51 52 53 54 5536[1] 36As you can see from the indices, these are three separate commands, because the numbered indices start over from [1] each time. However, we want all those numbers in a single command. To do this, we’ll use a function called c().
This is our first contact with functions in R, and we’ll explore how they work more later on. To use this one, type it out, then inside the brackets, put the numbers you want to collect (or concatenate, or combine), with different groups separated by commas.
c(12:30, 23:55, 36) [1] 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 23 24 25 26 27 28
[26] 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
[51] 54 55 36As you can see from the numbered indices this time, when I put the numbers I want inside the function c(), separated by commas, R collects all of the numbers into a single series of elements, called a vector.
Actually, we’ve been looking at vectors this whole time. When we were looking at single numbers (like 3958 above), we were still getting a vector back from R, but it was a vector with only one element, and thus only [1].
If I want the nth element in the vector we’ve just created, (say, the 33rd), I can get it out by indexing with square brackets.
c(12:30, 23:55, 36)[33][1] 36What I’ve essentially asked R is, “Put all of these numbers into a single vector, and then give me the 33rd element in that vector.” As it turns out, the 33rd element in that vector of numbers is 36.
A vector is essentially a series of pieces of data, or elements. It is a key basic piece of how data is stored in R. When R returns a vector as the output from a command, each element is numbered in square brackets. These square brackets can also be used to index the vector to get the nth element.
For atomic vectors created with c() or similar operations, there are some important rules:
For a complete explanation of vectors (and their more versatile siblings, lists) that’s beyond the scope of this tutorial, see:
This could be a very tedious process, but here we have an example of a vectorised operation. By default, the operation “subtract 7” is automatically applied to each individual element of the vector.
We can do a lot more than this with numbers and data in R, but this is an excellent start. Just one note before we move on about the order in which R performs its calculations.
Mathematical expressions are evaluated in a certain order of priority. You can use brackets to tell R which part of a longer calculation to do first, e.g.:
59 * (401 + 821)[1] 72098Without the brackets, the expression is evaluated from left to right, which in this case would give a different answer:
59 * 401 + 821[1] 24480Whenever there’s any chance for ambiguity, always use brackets to make sure the calculation is performed correctly.
Characters are a more general data category that also includes letters and words. In R, strings of letters or words must be enclosed in either ‘single’ or “double” quotes, otherwise R will try to read them as code:
Hello world!Error: <text>:1:7: unexpected symbol
1: Hello world
^"Hello world!"[1] "Hello world!"As you can see here, the first command without quotes throws an error, whereas the second prints out our input just like it did with the single numbers before. This tells us that unquoted strings have a particular role to play in R, whereas quoted strings are treated as character data.
An important thing to note is that R sees everything inside a pair of quotes as a single element, regardless of how long it is. You can see this in the indices we saw before:
"Hi!"[1] "Hi!""It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness..."[1] "It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness..."The [1] markers also tell us that each of the two strings above already constitute vectors, each of length 1. Just like we saw with numbers, above, any number of character strings can be combined into a vector. You can also use the numbered markers to extract the nth element in that vector.
The placement of the quotes is very important - they can’t include the commas. As we saw before, R uses commas to separate different elements. So, if you didn’t enclose each word in quotes separately with commas in between, you would have had this odd message:
c("bumblebee, squid, falcon, flea, seagull")[3][1] NANA is a special value in R. It indicates that something is not available, and it usually represents missing data.
Here, we asked R for the third element in a vector that, as far as R can tell, only contained one. This is because there’s only one pair of quotes, so all five animals and the commas between them are considered to be one element. Since there isn’t a third element, R has informed us so accordingly - the answer to our query is NA, not available, because it doesn’t exist.
Factors are a special type of data in R that are used to capture categorial data. They consist of two elements: the levels, which are the unique values that appear in the actual data; and the labels for each level, which usually contain information about what those levels indicate. As an example, we’ll consider a very common situation: a categorical vector of participant genders.
In data-gathering programmes such as Qualtrics, the levels are typically numeric, which correspond to particular gender categories. If we don’t supply any further information, we can use the factor() function to create a factor, and R will simply assign the levels as labels.
factor(c(1, 2, 1, 1, 1))[1] 1 2 1 1 1
Levels: 1 2However, this isn’t particularly helpful for interpreting these groups. Let’s say we know that in this case, 1 represents male and 2 represents female participants. We can then apply these labels to the levels. (Don’t worry too much about the code creating this factor for the moment - we will come back to working with factors in datasets later.)
factor(c(1, 2, 1, 1, 2),
labels = c("Male", "Female"))[1] Male Female Male Male Female
Levels: Male FemaleThe underlying values in the factor are numbers, here 1 and 2. The labels are applied to the values in ascending order of those values, so 1 becomes “Male”, “2” becomes “Female”, etc. Here, we don’t need to specify the levels; if you don’t elaborate otherwise, R will assume that they are the same as the unique values.
You can also supply additional possible values, even if they haven’t been observed, by explicitly providing the possible levels along with the labels.
factor(c(1, 2, 1, 1, 1),
levels = c(1, 2, 3),
labels = c("Male", "Female", "Non-binary"))[1] Male Female Male Male Male
Levels: Male Female Non-binaryFactors are an essential way to store and label categorical values in R. In a few weeks, we will have a look at how using factors or not can change the way your analyses run. For now, you only need to be aware that factors exist.
Factors are so common and useful in R that they have a whole {tidyverse} package to themselves! You already have {forcats} installed with {tidyverse}, but you can check out the help documentation if you’d like to learn more about working with factors.
The final type of data that we’ll look at for now is logical data. In addition to performing calculations and printing out words, R can also tell you whether a particular statement is TRUE or FALSE. To do this, we can use logical operators to form an assertion, and then R will tell us the result.
The last few statements above may have caused you some trouble if the notation is unfamiliar.
For “less than or equal to”, R won’t recognise the \(\le\) symbol. Instead, we combine two operators, “less than” < and “equal to” =, in the same order we’d normally read them aloud. The same goes for “greater than or equal to”, >=. (It does have to be this way round; try =< and => to see what happens.)
For “does not equal”, ! is common notation in R for “not”, or the reverse of something. So != can be read as “not-equals”.
For “equals”, if you tried this with a single equals sign, you would have had a strange error:
420 = 42Error in 420 = 42: invalid (do_set) left-hand side to assignmentThe problem is that the single equals sign =, like the comma, has some very specialised syntactic uses, including one equivalent to the assignment operator <-, which we’ll look at shortly. Single equals = also has an important and specific role to play in function arguments. Essentially, = is a special operator that doesn’t assert equivalence. Instead, “exactly equals” in R is “double-equals” (or “exactly and only”), ==.
Here R prints out a vector of TRUEs or FALSEs, one for each element in the original vector. So, the first element in the output (TRUE) corresponds to the statement 2 <= 6, the second to 3 <= 6, and so on. This is a vectorised calculation again, as we saw with numeric data before. These vectorised assertions will be absolutely essential to selecting and filtering data that meet particular requirements, or checking our data to find problems.
If you’re a regular SPSS user, you might recognise many of these data types from SPSS. See page 7 of this SPSS user guide for a reminder of these types.
So far, what we’ve called “numeric” in R is also (broadly) “scale/numeric” in SPSS. What we’ve called “character” in R is “string” in SPSS. Ordinal and Nominal data types in SPSS correspond (more or less) to factors in R. As far as I know, SPSS doesn’t have an equivalent of “logical”, but would probably be a “nominal/string” type.
We haven’t thus far talked about a few common data types that you might be used to using in SPSS. R also has date-time data, which is not covered in this series, but if you need to use it, check out the {lubridate} package.
With these short examples, it may be obvious just by looking that 25 is a number and porcupine is a word. However, this isn’t always so straightforward, and there are some situations - such as data checking/cleaning, or debugging - where we might want to check what type of data a certain thing is. To do this, we’ll need another new function, class(). This function will print out, as a character, the name of the data type of whatever is put into the brackets.
Something interesting has happened here. Recall that atomic vectors created with c() must all have the same data type. Here, we combined two types of data: numeric and character. We didn’t get an error - instead, without warning or telling us, R quietly converted the entire vector to character type. This forcible conversion is called coersion.
Coersion is when a piece of data is forcibly changed from one data type to another. This is sometimes intentional, but it can happen unintentionally (and without any warning or fanfare!), so is a common source of errors.
Coersion follows a hierarchy; data types on the left can be coerced into the types further along to the right.
logical ==> integer ==> double (numeric) ==> character
As we saw previously, you can check the data type of a vector with class(). You can also check if a vector is a particular type (and receive a logical vector in response) with the is.*() family of functions. (The * notation refers to a placeholder for many different options, such as is.numeric, is.character, etc.)
You can similarly (try to) coerce a vector into a particular data type with the as.*() family of functions.
This explains why our vector from the last exercise was a character vector - since the vector contained at least one character element, everything else in the vector was coerced to the same type. This can cause problems when, for example, numeric data is coerced into character data, even though it still looks like numbers.
Even though we can do mathematical operations on numbers, we can’t do them on characters; it should be clear that asking e.g. what is "tomato" - 7 is nonsense. However, this is the case even if all of the data are digits! For example:
## No problem here; all numbers
c(2:20, 45) - 7 [1] -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 8 9 10 11 12 13 38## Doesn't work
c(2:20, "45") - 7Error in c(2:20, "45") - 7: non-numeric argument to binary operatorEven though “45” looks like a number, because it’s in quotes, R thinks that it’s a character, and will refuse to do the calculation, in the same way that it would refuse to do it with “tomato”.
Here for the first time we see an example of a warning. Warnings are not errors, even though they get printed out in the same (usually alarming) colour and the same (often unfriendly) curt tone. The key difference is whether the code runs or not. With errors, the code cannot be executed as written, and the error is returned at the point where the execution failed. With warnings, the code CAN be (and has been) executed as written, but R is telling you that it has done something that you might not have expected or wanted along the way.
What we have asked in this command is for three pieces of data to be coerced to numeric type. The first, 20, is already numeric type, so presents no issue. The second, "42", is character type (because of the quotes), but is also parsable as a number so similarly presents no issue. The problem is "36 years old", which cannot be turned into a number3. Instead of throwing an error, though, R instead replaces "36 years old" in the output vector with NA, and prints a warning to let you know it’s done this. If this is what you wanted (and sometimes it might be), you can ignore it, but if you thought that all these ages were already numbers, this warning would be an important flag to investigate your data a bit more thoroughly.
R is a programming language, but (being created by speakers of natural language) it has many features similar or analogous to natural languages. In this section, we’ll cover the basic “grammar” of R, including how R understands what you ask it to do.
In a similar way that the basic unit of many languages is the word4, the basic unit of the R programming language is the object. This section will explore the basics of what an object is and some of their key features in R.
Objects are the basic elements that R is built around - the equivalent of words. An “object” in R is any bit of information that is stored with a particular name. Objects can hold anything, from a single number or word to huge datasets with thousands of data points or complex graphs. These named objects are the main way you, the programmer, can store, retrieve, and interact with information in R.
Although we have done quite a bit in R so far - creating vectors, doing calculations, etc. - you may notice that we haven’t stored this information anywhere. To store the output of code for further use, it needs to be assigned to an object using the assignment operator, <-. Once an object is created, it will appear in the Environment pane.
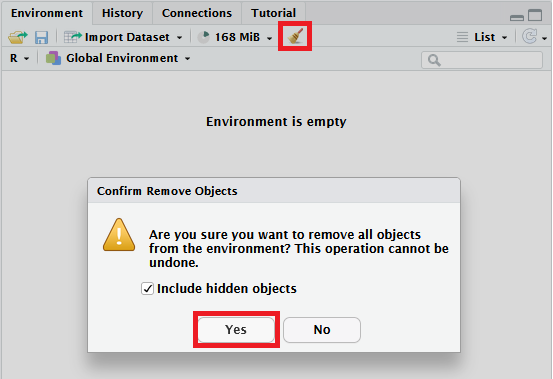
At the moment your Environment should be empty. As a reminder, Environment is by default the first (leftmost) tab in one of your four main windows in RStudio, probably the one on the top right.
If this window is blank except for “Environment is empty”, you’re ready to go. If for some reason it isn’t empty, click the broom icon to clear everything from your Environment before you get started, as indicted in the image below. (There will be a very ominous-sounding “Are you sure?” pop-up, but just click “Yes”.)
First, let’s look at the foundational structure of almost everything you will do in R:
object <- instructionsThis is “pseudo-code”, or a “general format” for a command in R. It isn’t valid R code, but is rather intended as a midpoint between natural language and R to help make it clear how the code works. You can read this code as, “An object is created from (<-) some instructions.”
object: Objects can be named almost anything (although see Naming Objects, below). The object name is a label so you can find, refer to, and use the information you need.<-: The assignment operator <- has single job: to assign output to names, or in other words, to create objects.instructions: Any amount of code that produces some output, which is what object will contain.Generally, you can name objects pretty freely in R (although see the boxes at the end for some advice). Object names must be a single sequence of symbols, so can’t include spaces or special operators (like =, <-, ,, etc.). The best idea is to come up with naming conventions that work for you, so you can easily remember what objects contain, and then be consistent as much as possible. R will let you know if you try to name an object something that it doesn’t like:
## This doesn't work because it would frankly be bonkers if it did
1285 <- "a"Error in 1285 <- "a": invalid (do_set) left-hand side to assignment## Can't start with a number...
1stletter <- "a"Error: <text>:2:2: unexpected symbol
1: ## Can't start with a number...
2: 1stletter
^## But numbers inside are okay
letter1 <- "a"
letter1[1] "a"## You can really go wild if you want, but this kind of thing is NOT recommended!
thisis_TheFirstLETTER.of.the.alphabetWOW <- "a"
thisis_TheFirstLETTER.of.the.alphabetWOW[1] "a"In these tutorials, we will typically stick to so-called “snake case” - lowercase names with underscores. This is generally the style of {tidyverse} as well. However, there’s nothing to stop you from using different conventions such as camelCase, PascalCase, whatever.this.is, or mixing them all at random, except maybe for the fact that your future self, and anyone else who might want to read or use your code, will almost certainly despair.
RepRoducibility: Good Object Names
Reading code is difficult. Regardless of how clear and obvious everything seems right now, in a few days, you will not remember what your code means. So, you want to make it as easy as possible for your future self to read your code. If you plan to share your code with other people (like a reproducibility officer) they would know even less about what your code does. The more legible your code is, the easier it will be to read, and the happier you and other people trying to run the code will be. The first step to help you achieve this is to use object names that are:
To illustrate what this means, let’s say you want to create two objects for quiz marks from students with practicals at 9am and students with practicals at 6pm. What would be some terrible names for these objects?
# Completely random names (not meaningful)
variable_1 <- c(75, 58, 62, 16, 33, 67)
variable_2 <- c(45, 90, 27, 65, 39, 77)
# Names abbreviated beyond comprehension (not understandable)
morn_qm <- c(75, 58, 62, 16, 33, 67)
after_qm <- c(45, 90, 27, 65, 39, 77)
# Names with too many words (not concise)
quiz_marks_of_students_who_have_morning_practicals_9am_gmt <- c(75, 58, 62, 16, 33, 67)
quiz_marks_of_students_who_have_afternoon_practicals_6pm_gmt <- c(45, 90, 27, 65, 39, 77)
# Names with varied formatting (not consistent)
morning_workshop_marks <- c(75, 58, 62, 16, 33, 67)
quiz_marks_6PM_practical <- c(45, 90, 27, 65, 39, 77)It is actually possible to use unallowable symbols, like spaces and punctuation, in some names, by using backticks. You must use the backticks when you create AND every time you use/call the object. It is generally a very bad idea to do this (just use underscores like a reasonable person), but it occasionally comes in handy for formatting tables or figures when the names don’t need to be machine-readable/good R code/easy to work with anymore.
nope this is bad <- "a"Error: <text>:1:6: unexpected symbol
1: nope this
^`but this one works!` <- "a"
`but this one works!`[1] "a"To get some practice with creating and working with objects, let’s get some data to work with.
Assuming your code is valid, you should see a green bar appear along the left-hand side of the code chunk when you run the code, but you might notice that there’s no printout that appears under the code chunk, as there was previously. In fact, if the code ran successfully, it might look like nothing happened at all. To find out what did happen, look your Environment pane. You should now see a new section, “Values”, and underneath the name of your new objects and what they contain. Success!
For any object, from the most simple to the most complex, you can always see what’s in it by calling the object. This simply means that you type the name of the object and run the code. R will print out whatever is stored in the object.
This output looks just like what we saw earlier, when we just asked R to print out a vector of numbers. In essence, the object names are just labels for storing and referring to the information they contain.
These two actions are the essential basis of everything you will do in R. All of your code will, at base, either create an object, or call an object. (Changing an existing object, as we’ll see shortly, is the exact same procedure as creating one from scratch.)
When you create an object using the assignment operator (<-), the object is created but is not printed out. This is because R always does only and exactly what you ask it to do, and using the assignment operator only tells R to assign something to an object, not to print it out6.
When you call an object, the current contents of that object are printed out, but that object is not changed - you only reproduce a copy of its contents for review. To create or change an object, you must use the assignment operator to assign the output to a new (or existing) object name.
Let’s make all of this a bit more concrete by seeing how we can use objects effectively.
Since objects are convenient reference labels for the information they contain, we can work with them as if they were the information they contain. In this case, our objects contain numbers, so we can use them for numerical calculations.
For instance, we might want to know what the mean mark was for this sample of quiz marks. To do this, we could make use of a very handy function, mean(), as follows:
mean(quiz_9am)[1] 51.83333You may have been surprised to see that the class of these objects is numeric, rather than character - even though the name of the object is a character string. To find out the class of the object, R looks at what that object contains, not at the name of the object itself. We already saw that quiz_9am (or whatever your object is called) contains only numbers; so, R tells us that it’s a numeric vector.
One more example to emphasize this point, because it’s often a source of confusion when starting out with R. If we want to ask R the class of the string “quiz_9am”, we would need to put it in quotes, and we’d get a different answer:
class("quiz_9am")[1] "character"The key thing here is that objects have the class of the data they contain, and are not character data; and whenever you want to use an object, you must not use quotation marks. On the other hand, if you want to input character data into R, you must use quotation marks. Otherwise, R will look for an object or function with that name, which will likely produce a “cannot find object” error.
Our last major point to cover with objects - for now - is how to change what an object contains.
The command we’ve just written for the task above demonstrates some extremely important properties of how assignment and functions work in R.
Overwriting objects is accomplished by assigning new output to an existing object name. If you have a look in your Environment, you will see that the previous version of quiz_9am, containing only six values, has been replaced with the new one containing nine values.
Overwriting objects is silent. Unlike, say, a word processor, that will give you a warning if you try to save two documents in the same folder with the same name, R won’t ask you if you’re sure you want to overwrite an existing object with new information - it will just do it. This can be a good thing, because you can easily update the information stored in an object with changes, edits, or new information. However, it also means that you can overwrite or replace data when you don’t want to, if you use the same object name.
This is why it is so important to keep track of all of the commands and changes you make to your data. If you accidentally replace your dataset with, say, a single word, or number with an error in your code, you can easily retrace your steps and avoid redoing work.
Overwriting objects can be done recursively. In the command we saw above, we took the current quiz_9am object, combined it with some new values, and then overwrote the quiz_9am object with the new values. If we were to run this exact same code again, this means that each time we would add three new values to quiz_9am, over and over and over:
quiz_9am <- c(quiz_9am, 89, 100, 79)
quiz_9am [1] 75 58 62 16 33 67 89 100 79 89 100 79quiz_9am <- c(quiz_9am, 89, 100, 79)
quiz_9am [1] 75 58 62 16 33 67 89 100 79 89 100 79 89 100 79This is one reason why the decision to overwrite an existing object, vs creating a new one, can make a big difference to your code. This behaviour only happens because the input and output objects are the same. If we name the output object something different, we don’t get the same recursion - the new object quiz_9am_full is recreated from the same input in the same way every time, so it always contains the same thing.
## Recreating the original version of quiz_9am so things don't get out of hand!
quiz_9am <- c(75, 58, 62, 16, 33, 67)
quiz_9am_full <- c(quiz_9am, 89, 100, 79)
quiz_9am_full[1] 75 58 62 16 33 67 89 100 79quiz_9am_full <- c(quiz_9am, 89, 100, 79)
quiz_9am_full[1] 75 58 62 16 33 67 89 100 79There isn’t a right or wrong way to do this - sometimes this recursive property is exactly what you want. (It’s very useful, for example, in loops.) But it is important to be aware of.
Finally, overwriting objects only changes the overwritten objects, and NOT any other objects created from them. To see this in action, recall that earlier we calculated the mean of the two quiz objects and saved it as quiz_diff. If we do the same calculation now with our updated objects, we can see that the difference in the means is no longer the same.
## Value calculated previously
quiz_diff[1] -5.333333## Value using the updated objects
mean(quiz_9am) - mean(quiz_6pm)[1] 11.44444## Ask R if the two are the same
quiz_diff == (mean(quiz_9am) - mean(quiz_6pm))[1] FALSEThis illustrates the importance of writing and running code sequentially, from beginning to end. If you go back and change values created earlier on in your code, the value you currently have in your Environment may not match the value that your code will produce when run.
If you are interested in understanding this process of assigning and replacing the contents of objects better, the aside below explains it in more depth.
The majority of this aside was originally written by Milan Valášek
Think of objects as boxes. The names of the objects are only labels, and you can store anything you like inside them. However, unlike in the physical world, objects in R cannot truly change. You can put stuff in and take stuff out, and that’s pretty much it. Unlike boxes, though, when you take stuff out of objects, you only take out a copy of its contents. The original contents of the box remain intact. Of course, you can do whatever you want (within limits) to the stuff once you’ve taken it out of the box, but you are only modifying the copy. The key thing to remember is that unless you put that modified stuff into a box, R will forget about it as soon as it’s done with it. In other words, if you want to “save” any changes you make, you must assign them to an object in order to keep them.
Now, as you probably know, you can call your boxes (objects) whatever you want (again, within certain limits). This means that that you can call the new box the same as the old one, as we saw with quiz_9am above. When that happens, R basically takes the label off the old box, pastes it on the new one, and burns the old box. So even though some operations in R may look like they change objects, what’s actually happening is that R copies their content, modifies it, stores the result in a different object, puts the same label on it, and discards the original object. Understanding this mechanism will make things much easier!
Putting the above into practice, this is how you “change” an R object:
# put 1 into an object (box) called a
a <- 1
# copy the content of a, add 1 to it and store it in an object b
b <- a + 1
# copy what's inside b and put it in a new object called a
# discarding ("overwriting") the old object a
a <- b
# now see what's inside of a
# (by copying its content and pasting it in the console)
a[1] 2Of course, you can just cut out the middleman (creating an object b). So to increment a by another 1, we can do:
a <- a + 1
a[1] 3
Let’s put all of this together and have a look at what we can already do with the skills in this tutorial. R has many, many uses, but one of its core purposes is statistical analysis - and we already know more than enough to do this.
We’ve created two objects that contain scores from two different groups - scores we made up, but we will get to real data soon. For now, one common statistical test we could run on data like this is a independent-samples t-test, which is a hypothesis test commonly used to test whether two sets of scores are likely to be sampled from the same underlying population or not.
Helpfully, the function we want is called t.test(). For our purposes, we can run the t-test by adapting the following general format:
t.test(vector_of_scores, another_vector_of_scores)Note that the output mentions “Welch Two Sample t-test”, which is a version of the test that does not assume equal variances. This is the version that is taught to undergraduates, because we have not at this point introduced the process of assumption testing. If you definitely know that the variances are equal and you definitely want Student’s t-test, you can instead change the default setting. Next time, we’ll look in more depth about how to work with functions and specify exactly how you want them to run.
In future tutorials, we’ll also see how to turn this rather ugly R output automatically into more nicely formatted reporting like this:
Effect sizes were labelled following Cohen’s (1988) recommendations.
The Welch Two Sample t-test testing the difference between quiz_9am and quiz_6pm (mean of x = 64.33, mean of y = 52.89) suggests that the effect is positive, statistically not significant, and small (difference = 11.44, 95% CI [-12.31, 35.20], t(15.08) = 1.03, p = 0.321; Cohen’s d = 0.48, 95% CI [-0.46, 1.42]).
RepRoducibility: Reproducible Analysis
We talked about overwriting objects earlier, but now that we have done some analysis, we should talk about it again. Overwriting objects can very easily break your code and introduce errors into your results.
Let’s say we that the quiz marks we compared were from practicals running on Monday. We also have some data from practicals running on Tuesday, and we want to repeat the exact same analysis on this new data7. We will use the same variables names for the morning and afternoon practicals across the two days:
# Quiz marks from Monday practicals
quiz_9am <- c(75, 58, 62, 16, 33, 67, 89, 100, 79)
quiz_6pm <- c(45, 90, 27, 65, 39, 77, 38, 42, 53)
# Compare the marks across the two sessions
monday_quiz_t_test <- t.test(quiz_9am, quiz_6pm, var.equal = TRUE)
monday_quiz_t_test
Two Sample t-test
data: quiz_9am and quiz_6pm
t = 1.0264, df = 16, p-value = 0.32
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-12.19206 35.08095
sample estimates:
mean of x mean of y
64.33333 52.88889 # Quiz marks from Tuesday practicals
quiz_9am <- c(45,62, 5, 0, 85, 52, 79, 100, 69)
quiz_6pm <- c(25,42, 15, 10, 72, 55, 89, 89, 65)
# Compare the marks across the two sessions
tuesday_quiz_t_test <- t.test(quiz_9am, quiz_6pm, var.equal = TRUE)
tuesday_quiz_t_test
Two Sample t-test
data: quiz_9am and quiz_6pm
t = 0.2557, df = 16, p-value = 0.8014
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-28.35175 36.12953
sample estimates:
mean of x mean of y
55.22222 51.33333 If you run each line sequentially, the contents of the object monday_quiz_t_test will be different from tuesday_quiz_t_test and the results you get for both will be correct. This is because the objects quiz_9am and quiz_6pm are overwritten with the Tuesday marks before the t-test for the Tuesday data is run.
Now, say that after you ran the chunk of code above, you run the following line again:
monday_quiz_t_test <- t.test(quiz_9am, quiz_6pm, var.equal = TRUE)
monday_quiz_t_test
Two Sample t-test
data: quiz_9am and quiz_6pm
t = 0.2557, df = 16, p-value = 0.8014
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-28.35175 36.12953
sample estimates:
mean of x mean of y
55.22222 51.33333 Compare these results to above. The “Monday” object, monday_quiz_t_test, now contains the results for the Tuesday data.
If you always meticulously execute your code line by line from start to finish, you won’t run into this issue. But, as time goes on, you may notice that this is not the most user-friendly way to interact with a script, and you may find yourself running lines of code in non-sequential order.
This is especially the case if you are running someone else’s code. When doing a reproducibility check, the first thing I (Reny) do is run the whole script to see if there are any errors, and only then do I go back and rerun different bits and pieces of the code to check the actual results.
A key aspect to writing reproducible code is that the code should be flexible and resilient – it should always provide the same output regardless of the unexpected ways a person might run the code.
So, how can we make the code above less prone to these kinds of mixups?
# Quiz marks from Monday practicals
quiz_monday_9am <- c(75, 58, 62, 16, 33, 67, 89, 100, 79)
quiz_monday_6pm <- c(45, 90, 27, 65, 39, 77, 38, 42, 53)
# Compare the marks across the two sessions
monday_quiz_t_test <- t.test(quiz_monday_9am, quiz_monday_6pm, var.equal = TRUE)
# Quiz marks from Tuesday practicals
quiz_tuesday_9am <- c(45,62, 5, 0, 85, 52, 79, 100, 69)
quiz_tuesday_6pm <- c(25,42, 15, 10, 72, 55, 89, 89, 65)
# Compare the marks across the two sessions
tuesday_quiz_t_test <- t.test(quiz_tuesday_9am, quiz_tuesday_6pm, var.equal = TRUE)Here, instead of overwriting the quiz_9am and quiz_6pm objects with new information, we’ve named all of the objects containing scores with unique names. Now we no longer have to wonder which score information we are using; rather, our t.test() functions only work with exactly the right data.
In other cases, overwriting objects can have different effects such as causing errors that stop your code from running, but we will look into examples of these in future sessions.
This isn’t technically true - have a look at the “History” tab in the Environment window. However, the commands stored here can’t be run or used - they have to be copied into the Console or Source windows in order to run. The History tab provides an exhaustive record of the things you’ve typed, not a cohesive or meaningful series of steps.↩︎
Don’t get me wrong - crashes do happen! But they often look like a “fatal error” popup message, the programme freezing, or other obvious breakdowns of the programme itself. “Errors” in code as we’re seeing here are just a part of the normal functioning of R and don’t usually mean anything particularly horrific is occurring.↩︎
Well, not in the single command we’re using here. We can certainly get out the age 36, but it will take a bit more work - and maybe some regular expressions.↩︎
As a linguist I (Jennifer) have to note, one, words don’t exist, and two, the closest linguistic term for what an object is is probably “lexeme”. “Word” will get you in the right vicinity, though, conceptually. If you’d like to dive down this rabbit hole (rabbit-hole?) this Crash Course video on morphology is a good place to start.↩︎
Again, I could have called this object anything, like the_first_example_of_an_object_InThisSection.so.far or made_upQuizScores.fornineamclass or anything else that follows R’s naming conventions. However, it’s a good idea to name your objects something brief and obvious, so you can remember what they contain and work with them easily. ↩︎
There is a way to do this - you can enclose the entire expression in round brackets, e.g. (object <- instructions), which will BOTH create the object AND print out what that object contains at the same time. I’m not using this method in these tutorials because I think it will be confusing, since it’s primarily for demonstration purposes and not necessary the sort of thing you’d want to use in your own analysis code.↩︎
We will ignore whether this is an appropriate thing to do statistics wise!↩︎