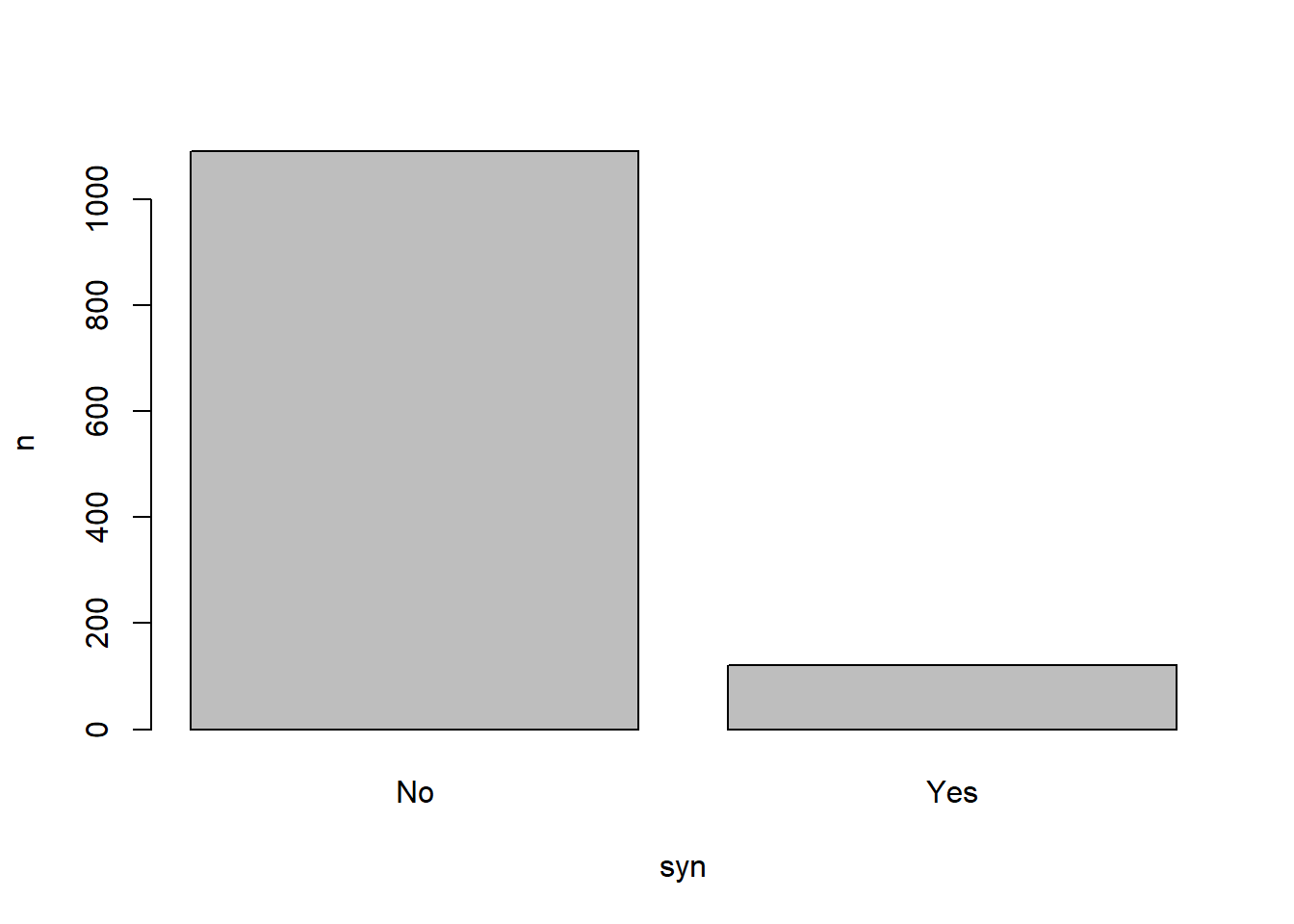This tutorial is focused on working with datasets. It covers key functions and tips for reading in, viewing, and summarising datasets. It also introduces the pipe operator and a variety of common descriptive functions for investigating both whole datasets and individual variables, and concludes with a brief look at data visualisations with base R.
Setup
In each session, we will always follow the same steps to set up. We’ll walk through the key elements here in detail and then provide a brief summary in future tutorials.
Projects are the main way that RStudio organises related files and information. Projects are associated with a working directory; everything in that directory, including all the sub-folders, are part of the same project.
It is highly recommended that you create a new project for each separate thing you want to work on in R. Among other advantages, it makes navigating folders much easier (see Reading In), allows you to easily pick up work from where you left off, and retain all the settings and options you have set each time you work on the same project.
Creating a Project
On Posit Cloud, you don’t really have a choice in the matter - you must create or open a project in the Cloud workspace in order to do anything.
On a desktop installation, you can create a new directory as a project or associate a project file with an existing directory.
As we discussed in the previous tutorial, one of the key strengths of doing your work using R (or any other programming language) is reproducibility - in other words, every step of the process from raw file to output is documented and replicable. However, this is only the case if you do in fact write your code down somewhere! To do that, you’ll need to create some kind of document to record your code. There are two main types of documents you might consider using: a script or a Quarto document.
Quarto documents
Quarto documents contain a combination of both non-code text and code. The main strength of these documents is that they can be rendered to some other output format, such as HTML, PDF, or Word, by executing all of the code and combining it with the text to create a nicely formatted document.
We will investigate the options for Quarto documents in depth in the next tutorial. For now, use the Quarto document in your project on Posit Cloud for your work in this tutorial.
Scripts
Scripts are text files that RStudio knows to read as R code. They have a .R file extension and can ONLY contain code. They are very useful for running code behind the scenes, so to speak, but not great for reviewing or presenting results.
Quarto or Script?
When deciding what kind of document to create, think about what you want to do with the output of your work.
Use Quarto if the document needs to contain any amount of text, or will be used to share the output of your code in a presentable way, such as notes for yourself, reports, articles, websites, etc.
The page you’re reading now is (or was!) a Quarto document.
Use a script if the document only needs to contain code and has a solely functional purpose, such as cleaning a dataset, manipulating files, defining new functions, etc.
I use a script to process all of the tutorial documents and generate the Quick Reference page.
In this series, we will almost always use Quarto documents, but scripts are an essential part of the development side of R.
Installing and Loading Packages
In the previous tutorial, we saw how the main way that R does anything is via functions. All functions belong to a package, which are extensions to the R language. Packages can contain functions, documentation for those functions, datasets, sample code, and more. Some packages, like the {base} and {stats} packages that contain the mean() and t.test() functions that we saw previously, are included by default with R. However, you will often want to use functions from packages that aren’t included by default, so you must do this explicitly.
In order to utilise the functions in a package, you must do two things:
Install the package (only once per device, or to update the package) using install.packages("package_name")in the Console
Load the package (every time you want to use it) using library(package_name)at the beginning of each new document
Important
If you are working on these tutorials on the Posit Cloud workspace, all of the packages you need have been installed already. Please do not try to install any packages, as this could cause unexpected conflicts or errors.
More About Installing vs Loading Packages
When you install R and RStudio for the first time on a device, this is like buying a new mobile phone. When you get a new phone, it comes with some apps pre-installed, like a messaging app, a camera, a calculator, etc. If you only ever wanted to take pictures and do basic maths with your phone, you could probably leave it at that. Most likely, though, you want to use other apps that don’t come with the phone - like WhatsApp, or Facebook. Let’s say you’ve just got a new phone and you want to use WhatsApp. To do this, you’ll need to:
Go to your phone’s app store and download WhatsApp (only once per device, or to update the app)
Open the app (every time you want to use it)
As you can see, these steps correspond almost exactly to the installing vs loading steps described above. In order to use a package that doesn’t come pre-installed with R, you have to do both of these things.
Exercise
Load the {tidyverse} package in your Quarto document.
Solution
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.3 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.0
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
When you load {tidyverse} for the first time, quite a lot of extra stuff gets printed along with it. All this output looks alarming, but these aren’t errors or warnings - they’re just messages. Messages are like warnings, but neutral: they just contain information that you might find helpful.
The usual {tidyverse} message contains two parts:
Attaching core tidyverse packages tells you which packages have just been loaded. Essentially, library(tidyverse) is a shortcut for loading all of these packages individually. Somewhat confusingly, installing {tidyverse} installs more packages than are in this list (for example, {magrittr} and {rlang}), many of which other {tidyverse} packages rely on to function. If you want to load them, you can use library() to do this - but you don’t need to unless you’re using those packages explicitly. For our purposes now, just the default {tidyverse} packages are fine.
Conflicts tells you about any package conflicts as a result of loading the packages. If you’re curious, conflicts are explained further in the callout box below.
Conflicts
There are lots and lots of packages for R. At the time of this writing, CRAN (the repository for R packages) contains just shy of 20,000 R packages, with many, many more on Github and elsewhere. Although people generally try to avoid it, it is necessarily the case that sometimes, people give the same name to two different functions from two different packages.
So, if you have those packages both loaded, how does R know which one to use? This situation is called a conflict, and is resolved in a few different methods.
Method 1: Recency
In the absence of any other information, R will use the function from the package that was loaded most recently. This is exactly what’s happening in the {tidyverse} message above.
There are two conflicts mentioned. one of which reads:
x dplyr::filter() masks stats::filter()
{stats}, you might remember, is a package that is always installed with R and is loaded by default. So, the {stats} package has a function called filter() that is already loaded to begin with. When we loaded {tidyverse}, one of the new packages, {dplyr}, also contains a function called filter(). Because {dplyr} has been loaded more recently, if you write a bit of code using filter(), the one you will get is dplyr::filter()1. In other words, the more recently loaded dplyr::filter() covers over, steps in front of, or (in R terminology) “masks” stats::filter().
Now, what if you actually want to use filter() from {stats} instead? Well, in that case you might want to use…
Method 2: Explicit style
Above we saw several examples of the package::function() notation, called “explicit” or “verbose” coding style. With explicit style, there isn’t actually a conflict between stats::filter() and dplyr::filter() anymore, because their package calls are clearly stated so R doesn’t have to guess which filter() you want. So, if you had loaded {tidyverse}, you could write stats::filter() in your code, and you would still get the function from the {stats} package even with {dplyr} loaded.
Another, secret benefit of explicit style is that as long as you have a package installed, you can use a function from that package without having to load it. Imagine I start a new project (so I have stats::filter() already loaded by default). If I only want to quickly use dplyr::filter(), I can use explicit style to use that function without having to run library(tidyverse).
The style you’ll see in these tutorials is a pretty devotedly explicit style: that is, I’ll always write dplyr::filter() instead of just filter(). I only leave out the package name in a few situations:
When the function is from a default-loaded package, like {base} or {stats} (so I write mean() instead of base::mean()). This is mostly just convenience!
When there are lots of functions from the same package in row, all of which have very distinctive names, that would make reading the code very difficult and writing the code very repetitive. This is the case, for example, with {ggplot2}, which we will encounter in the next section of the course. For cases like this, I make sure to explicitly load the relevant package and then leave off the package name.
I like explicit style because I never have to deal with package conflicts; I rarely have to load packages; and it helps me understand better how my code works. You don’t have to use it, and most of the time it won’t make that much difference, so do what makes sense to you. Just to be safe, though, we’ll load {tidyverse} regularly.
Reading In
Now that we’ve completed our core setup, we’re ready to get stuck in working with datasets. For the purposes of practicing, we’re going to use some real, open-source data from a real paper by Mealor et al. from their (2016) paper developing the Sussex Cognitive Styles Questionnaire (SCSQ). The SCSQ is a six-factor cognitive styles questionnaire validated by comparing responses from people with and without synaesthesia.
We’re going to start by importing, or “reading in”, the data from a location outside of R. The first job is to work out how that data is stored: the file format that it’s in, and the location we need to give to R to look for it.
For the purposes of these tutorials, we’ll primarily make use of .csv file types when reading in. CSV (Comma-Separated Values) is a common, programme-agnostic file type without any fancy formatting, just plain text. To practice this, we’ll use the read_csv() function from the {readr} package (part of {tidyverse}).
One advantage of readr::read_csv() is that it will output a special kind of dataset, called a tibble. Tibbles are a fundamental component of {tidyverse}. They are a sort of embellished dataframe or table (“table” > “tbl” > “tibble”) with some extra bells and whistles for convenience. We’ll discover their features as we go, but you can get a quick overview of tibbles here.
Reading Other Filetypes
If you have data stored in other types of files, you may need other functions from other packages to read them in. It will depend substantially on what’s in the file and how the data are structured, so you will likely need to do some experimentation to find the best option.
Here are some possibilities to get you started. All of them (except the last) output a tibble.
Excel (xlsx): readxl::read_xlsx()
SPSS (.sav): haven::read_sav()
SAS (.sas): haven::read_sas()
JSON: rjson::fromJSON()
Our next job is to figure out where the data is stored. For the purposes of practice, we’ll look at two possibilities. First, that the data is stored in a local file on your computer; and second, that the data is hosted online somewhere, accessible via URL.
Reading from File
The scenario you are most likely to encounter is that you have some data in a folder on your computer, and you’d like to import, or “read in”, this data to R so you can work with it. To practice this, in your Posit Cloud project there is a folder named “data” that contains a file called “syn_data.csv”. (If you are not on the Cloud, skip down to the next section.)
In order to use the read_csv() function, we need to give it the file path as a string (i.e. in "quotes"). Let’s make this easier by using a helper function: here::here().
Exercise
Run the here::here() function to see what it does.
What you should get is a string - a file path to the project you are currently in. On Posit Cloud, this will always be “/cloud/project” (unless you change it). In any case, it will always point to the location of the .Rproj file that denotes your current project.
Why is this useful? Instead of having to write out long file paths (“C/Users/my_folder/What Was It called-again?/…”), or trying to figure out where your current file is relative to the data (or image, or whatever) that you are trying to find, here::here() uses the project file as a fixed point. So, all file paths can be written starting from the same point.
Exercise
Use here::here() to generate a file path to the syn_data data file.
Then, use readr::read_csv() to read in the syn_data.csv file and store the result in an object called syn_data.
Solution
Assuming you are on the Cloud, your here::here() command should look like this. The first part of the file path will be generated by here::here() up to the project file; from there, we look in the data folder, in which we can find the syn_data.csv file. (Don’t forget the .csv file extension!)
here::here("data/syn_data.csv")
To read in the file, we add two things. First, we put the here::here() command - which outputs the file path - into readr::read_csv(), which actually imports the data at that file path into a tibble. Then, we save that tibble into an object called syn_data using the assignment operator, <-.
If the data is hosted somewhere online, you can give the hosting URL to R as a string. Assuming you have an Internet connection (!), R will go to that URL and parse the data.
As this dataset is likely unfamiliar, the codebook below explains what the variables in this dataset represent.
More About Synaesthesia
This dataset focuses on cognitive styles, particularly in people with and without a neuropsychological condition called synaesthesia. Synaesthesia is colloquially referred to as a “blurring of the senses” that can manifest in many different ways. For example, some people with synaesthesia may percieve colours associated with letters or words, or see shapes when they hear music. These additional perceptions are typically automatic and consistent across time.
This particular study focused on two different types of synaesthesia: grapheme-colour and sequence-space. People with grapheme-colour synaesthesia experience colour associated with written language, i.e. graphemes. For instance, the letter “Q” may be purple, or the word “cactus” may be red (or a combination of colours).
People with sequence-space synaesthesia associate sequences, such as numbers, days of the week, or months of the year, with particular locations in physical space. For instance, Monday may be located up and to the right, or July near the hip. Sequence-space synaesthetes can often precisely describe and point to the specific location of each element of the sequence.
There are also a variety of qualities associated with having synaesthesia of any type, so this dataset also includes a variable coding for having either (or both) types.
Variable Name
Type
Description
id_code
factor
Participant ID number
gender
factor
Participant gender, 0 = female, 1 = male
gc_score
numeric
Score on the grapheme-colour test of the Synesthesia Battery (Eagleman et al., 2007). Scores of 1.43 or lower indicate genuine synaesthesia (Rothen et al., 2013)
syn
factor
Whether the participant is a synaesthete (Yes) or not (No), regardless of type of synaesthesia
syn_graph_col
factor
Whether the participant has grapheme-colour synaethesia (Yes) or not (No)
syn_seq_space
factor
Whether the participant has sequence-space synaethesia (Yes) or not (No)
scsq_imagery
numeric
Mean score on the Imagery Abilitysubscale of the SCSQ
scsq_techspace
numeric
Mean score on the Technical/Spatial subscale of the SCSQ
scsq_language
numeric
Mean score on the Language and Word Forms subscale of the SCSQ
scsq_organise
numeric
Mean score on the Organisation subscale of the SCSQ
scsq_global
numeric
Mean score on the Global Bias subscale of the SCSQ
scsq_system
numeric
Mean score on the Systemising Tendency subscale of the SCSQ
Viewing
We’ve now got some data to work with! Before we jump into doing anything with it, though, we should take a look at it. This is always a good idea to check that our data has read in correctly without any parsing errors. But our data is tucked away in an object! How can we take a look at it?
Call the Object
Our first option is to call the object that contains our data. This is almost always an easy and straightforward way to get an instant look at what’s in our data.
Exercise
Call the syn_data object to see what it contains.
Solution
syn_data
You may notice a few of those “bells and whistles” I mentioned earlier here.
By default, tibbles like this one only print out up to the first ten rows at a time, and as many columns as conveniently fit in your current window size.
You can scroll through this printout by clicking the numbers at the bottom (to move through rows) or the left and right arrows at the top (to scroll through columns).
Each column has a little tag underneath it to tell you what kind of data is currently stored in it, for example <dbl> for numeric/double and <chr> for character.
In the top left, the little box tells you what it is (“A tibble”) and the size of the dataset (“1211 x 12”).
Warning
There’s a big caveat here: this works great with tibbles. For data stored in other formats, like matrices, there’s no preset formatting like this. If you accidentally call the name of an object that contains thousands of rows, R will try to print them all, which can lead to crashes. So, avoid calling very large objects directly like this if they aren’t tibbles.
A Glimpse of the Data
As mentioned above, just calling the dataset isn’t always super helpful - it depends on the size of your screen and even the width of your current window! As the next step, let’s get an overview of this dataset using the glimpse() function from the {dplyr} package.
Exercise
Use dplyr::glimpse() to get a glimpse of your dataset.
This gives us a nice overview of all the variables we have in the data (each preceded by $, which we’ll come back to in the second half); what kind of data they are (e.g. <chr>, <dbl>, and so on); and a look at the first few values in each variable. This is a great way to check that all the variables you expect to be there are there, and that they contain (more or less) what you thought they should.
But what if we really want to get a look at the entire dataset? For that we need…
View Mode
We can have a look at the whole dataset more easily - and interact with it to some degree - by viewing it, which opens a copy of the dataset in the Source window to look through. We can do this with the View() function (note the capital “V”!).
Exercise
Open the syn_data dataset using the View() function in the Console.
Solution
View(syn_data)
This View mode has a few very handy features. Take a moment now to explore and work out how to do the following.
Exercise
Using only View mode, figure out the following:
What is the range of the variable gc_score?
How can you arrange the dataset by score in scsq_imagery?
How many participants had “Yes” in the variable syn_graph_col?
Which gender category had more participants?
Of the participants who said “Yes” to syn_seq_space, what was the highest SCSQ technical-spatial score?
Solution
Hover your mouse over the variable label gc_score to see a tooltip reporting the range.
Use the small up/down arrows next to each variable label to reorder the dataset by the values in that variable.
Click on the “Filter” button in the top left to open filter view. Then, click on the text box under syn_graph_col and type “Yes”. You can now see a dataset with only the Yes responses.
In filter view, click on the text box under gender to open a histogram of the values in this variable.
In filter view, click on the text box under syn_seq_space and type “Yes”. Then, use the up and down buttons to arrange in descending order for the variable scsq_techspace.
These features are really useful to have a quick poke around the data or check that everything is in order. However, keep in mind an important point: None of the changes made in View mode affect the data. View mode is essentially read-only; there’s no way to actually change the dataset or extract the values (like the range or max value) outside of copying them down by hand2. We’ll have to use R to work with the data in order to do that.
No Touching
If you are used to programmes like SPSS or Excel, where you can directly edit or work with the data in the spreadsheet, switching to R can be quite a frustrating change. Even though View mode looks similar, it’s like the dataset is behind glass - you can’t affect it directly. As we start working with the data via objects and functions, it may feel a bit like you are trying to work blindfolded - you can’t actually “see” what you are doing as you do it.
If you feel that way, be reassured that it’s normal. Working with objects rather than with spreadsheets or data directly takes some getting used to, and it will get easier with practice. Use View() freely to check your work - I do!
Overall Summaries
We’ve now gained some confidence that our data looks like data should. We got a look at some summary information in View mode, but although this might have been useful for us in our initial checks, we can’t easily record or reproduce that information. Next, we’re going to look at some options for getting summary information about the whole dataset.
Basic Summary
The quickest and easiest check for a whole dataset is the base R function summary(). This function doesn’t do anything fancy (at all) but it does give you a very quick look at how all the variables have been read in, and an early indication if there’s anything exciting wonky going on.
Exercise
Print out a summary of syn_data using the summary() function.
Solution
summary(syn_data)
id_code gender gc_score syn
Min. : 1.0 Min. :0.0000 Min. :0.3500 Length:1211
1st Qu.: 303.5 1st Qu.:0.0000 1st Qu.:0.5600 Class :character
Median : 606.0 Median :0.0000 Median :0.7200 Mode :character
Mean : 606.0 Mean :0.1982 Mean :0.7558
3rd Qu.: 908.5 3rd Qu.:0.0000 3rd Qu.:0.8750
Max. :1211.0 Max. :1.0000 Max. :1.4000
NA's :1168
syn_graph_col syn_seq_space scsq_imagery scsq_techspace
Length:1211 Length:1211 Min. :1.240 Min. :1.24
Class :character Class :character 1st Qu.:3.410 1st Qu.:2.41
Mode :character Mode :character Median :3.760 Median :2.82
Mean :3.715 Mean :2.86
3rd Qu.:4.060 3rd Qu.:3.29
Max. :5.000 Max. :4.88
scsq_language scsq_organise scsq_global scsq_system
Min. :1.000 Min. :1.000 Min. :1.000 Min. :1.000
1st Qu.:3.000 1st Qu.:2.670 1st Qu.:2.500 1st Qu.:2.170
Median :3.670 Median :3.170 Median :2.880 Median :2.670
Mean :3.581 Mean :3.109 Mean :2.939 Mean :2.672
3rd Qu.:4.170 3rd Qu.:3.670 3rd Qu.:3.380 3rd Qu.:3.170
Max. :5.000 Max. :5.000 Max. :5.000 Max. :4.830
Here, for example, notice the gender variable. This is intended to be a categorical variable, but clearly something has gone pear-shaped, because it has read in as a numeric variable. We have a related, but different issue with the syn_* variables, which also should be categorical (“Yes” and “No”), but instead have been read as numeric. Our other variables, gc_score and the scsq variables, should contain numeric information and it appears they do; for them, we get some helpful information and measures of central tendancy.
We will ignore the categorical issue for now until we cover how to make changes to the dataset in the next tutorial.
summary() is quick, and because it’s a base-R function, it doesn’t need any package installations to work. However, it’s also of limited use: its output is ugly, and it would be pretty difficult to get any of those values out of that output for reporting!
Other Summaries
Besides the basic summary, there are many ready-made options in various packages to quickly produce summary tables. At the UG level, students are introduced datawizard::describe_distribution(), which is one such function. To use it, simply put the name of the dataset object inside the brackets.
Tip
Besides its default settings, the output can be further customised to add or remove particular statistics; see the help documentation.
Exercise
Print out a summary of syn_data using the datawizard::describe_distribution() function.
Solution
datawizard::describe_distribution(syn_data)
Exercise
CHALLENGE: There are some variables missing from this output. What are they? Why aren’t they included?
Solution
The two character variables, syn_seq_space and syn_graph_col, are missing from the output. Under Details, the help documentation says: “If x is a data frame, only numeric variables are kept and will be displayed in the summary.” Since these are not numeric variables, they’ve been dropped.
The Pipe
Before we go on, we’re going to meet a new operator that will form the core of our coding style from this point onwards: the pipe. We’ll begin working with it a bit today, so let’s first explore why it’s so useful.
In this and the previous tutorial, we’ve seen some examples of “nested” code - functions nested within functions, as below.
round(mean(quiz_9am), digits =2)
To read this code, you have to start at the innermost level of nesting and work outwards. So, first R gets the quiz_9am object; then calculates the mean using mean(); then the output of mean() is the input to round(). For one or two levels of nesting, this is still legible, but can quickly become very difficult to track.
One solution is to use the pipe operator, |>. The pipe “chains” commands one after the other by taking the output of the preceding command and “piping it into” the next command, allowing a much more natural and readable sequence of steps - sequentially, rather than nested. The pipe version of the above might look like this:
quiz_9am |>mean() |>round(digits =2)
This style maps on a lot more naturally to how we would read or understand the steps in this command in natural language.
Definition: Pipe
The pipe operator may appear in two formats.
The native pipe, |>. This is the pipe we will use throughout these tutorials. It is called the “native” pipe because it is inbuilt into R and doesn’t require any specific package to use.
The {magrittr} pipe, %>%. This pipe comes from {tidyverse}, and in particular requires the {magrittr} package to use. You will very commonly see this pipe in scripts, Stack Overflow posts, from ChatGPT, etc. as until the native pipe was introduced to R in 2022, the {magrittr} pipe was “the pipe” for R.
In most cases, including almost all of the code we will learn in these tutorials, the two pipes are interchangeable and will result in the same output.
Conceptually, the pipe works taking the output of the code on the left and passing it, by default, into the first unnamed argument of whatever comes after it on the right3. Many functions - both from the {tidyverse} and not - are already set up so that the first argument is the data, and {tidyverse} functions are explicitly designed this way in order to work best with the pipe.
For functions where this is not the case, you can determine where the piped-in information should go using a “placeholder”. The most noticeable difference between the two pipes is that they have different placeholders. The native pipe (|>) uses underscore _ as its placeholder, while the magrittr pipe (%>%) uses the dot/full stop . There’s an example using placeholders below to help make this clearer.
From this point forward, we’ll start working with the native pipe. The following sections will have specific examples on using the pipe to practice. Working with the pipe is also a good chance to practice “translating” R code into English, which we’ll do as we go. To give you an idea, here’s an example of how we can read the following code. We’ll typically read |> as “and then”, taking the output of whatever the preceding line produces and passing it on to the next line.
Create a new object, some_numbers, that contains a vector of some numbers.
2
Take some_numbers, and then…
3
Calculate the mean of those numbers, and then…
4
Round that mean to two decimal places, which outputs:
[1] 6.37
It might seem strange that these functions appear to be “empty”. Take the third step above, which just reads mean(). There’s nothing in the brackets, so it appears that the mean() function is working on nothing! However, remember that the pipe passes whatever is on its left-hand side (abbreviated LHS) to the first unnamed argument of the function on its right-hand side (RHS). In this example, the object some_numbers is the input on the LHS, which is being “piped into” the first unnamed argument of the mean() function on the RHS, which is x, the data or values to work with. We don’t have to explicitly specify this; it’s just how the pipe works by default.
To illustrate this more clearly, here’s the same code explicitly including the placeholders to indicate where the piped-in information goes:
Think of the placeholder like a bucket or landing pad, where the information coming in from the pipe falls. In this example, the placeholders aren’t necessary, because at each step, we already want the piped-in information to go into the first argument, which we have left unnamed, and which is conveniently, in both cases, x, the data or values to work with; but including the placeholders (and, necessarily if we want to use placeholders, the argument names) helps to see what’s going on.
To make this fully explicit, this illustration shows the progress of information through the same pipe. The orange arrows show how the piped-in information is passed from one function to the next. The teal arrows show what is produced at each step of the pipe - which is what is passed on to the next function via the orange arrows/pipe.
A Sweet Pipe Example
Imagine we wanted to bake a Victoria sponge cake using R. Translating the steps into R, we might get something like this:
At each step, |> takes whatever the previous step produces and passes it on to the next step. So, we begin with ingredients - presumably an object that contains our flour, sugar, eggs, etc - which is “piped into” the mix() function. The output of that function might be all our ingredients mixed together in a bowl, which is then piped into the pour() function, and so on.
Notice for example, the function cool(), which doesn’t appear to have anything in it. It actually does: the cool() function would work with whatever the output of the bake() function was above it: a freshly baked cake straight out of the oven.
Without the pipe, our command might look something like this, which must be read from the inside out rather from top to bottom:
The new line after the pipe isn’t essential (it will run exactly the same way) but it is highly recommended. Although it doesn’t make much of a difference here, we will shortly get to longer commands where the new line for each new function will make a big difference to legibility!
What’s Going On With the Pipe?
If a command like syn_data |> names() looks a bit strange, let’s take a closer look at it.
This command is equivalent to names(syn_data), which might look a bit more familiar based on what we’ve done so far. The pipe takes whatever comes before it - in this case, the dataset syn_data - and pipes it into the first argument of the function that comes after it. The names() function only accepts one object as input, so syn_data is passed to names() as that single object. It looks like the names() function is empty, because there’s nothing in the brackets, but that’s because the dataset is being “piped in” from above.
We can make this a bit more explicit using the placeholder:
The underscore is the “placeholder” for the native pipe; in other words, it explicitly indicates where the object should be placed that is being piped in, like a “bucket” that catches whatever comes out of the pipe! This makes it a bit clearer to see that the object syn_data is going into the names() function, and specifically the x argument.
Exercise
Using the native pipe, save the number of participants in the syn_data dataset in a new object of your choice.
Solution
px_initial <- syn_data |>nrow()
This format takes a bit of getting used to. The new object, which I’ve called px_initial4, is created at the first line of the command by the <-. However, this object contains whatever the final output of this pipe is at the end - in this case, the number of rows as a numeric value produced by nrow().
Describing Variables
Once we’ve had a look at the whole dataset, it’s time to drill down into individual variables. We may want to calculate quick descriptives or investigate what’s going on with particular variables that seem to have issues.
To do this, we’ll start working quite a bit with the {dplyr} package. {dplyr} is a core part of the {tidyverse}, and the package generally is focused on user-friendly and easily readable tools for data manipulation. The essential {dplyr} functions will form a core part of the Essentials part of the course, when we really get into to working with data.
Counting
We’ll start by having a look at character or categorical variables. Here we’ll meet our first {dplyr} function: dplyr::count(). This function is a friendly way to obtain (as you might expect!) counts of the number of times each unique value appears in a variable. As with just about everything in {dplyr}, it takes a tibble as input and produces a new tibble as output.
Using the pipe structure we’ve seen previously, the general form is:
Minimally you need to provide a single variable to count the values in, but you can add more, separated by commas, to further subdivide the counts.
Exercise
Using the syn_data dataset, produce a tibble of counts of how many participants had any kind of synaesthesia. Then, produce a second tibble, adding in gender as well.
Hint: Use the codebook to find the variables to use.
Solution
syn_data |> dplyr::count(syn)
syn_data |> dplyr::count(syn, gender)
As you can see, the output from this function is a new summary tibble containing only the unique values in each variable, and a count, in the new “n” variable, of how many times that value (or combination of values) appeared.
Note that this does not change or add anything to your original dataset! Instead, this function creates a brand-new tibble with the requested information.
Subsetting
To work with individual variables, we need to get them out of the dataset. Specifically, for many of the functions we’re about to use, we will need the values stored in those variables as vectors. We can do this in two ways: $ notation, or the function dplyr::pull()5.
Subsetting with $ is the base-R method, and it takes the general form:
dataset_name$variable_to_subset
Subsetting with dplyr::pull() is a {tidyverse} method of accomplishing the same thing. Using the pipe structure we’ve seen previously, the general form is:
dataset_name |>
dplyr::pull(variable_to_subset)
Exercise
Subset syn_data using $ to get out all the values stored in the scsq_organise variable.
Solution
To keep this tutorial legible, I’ve only printed out the first 10 values.
Subset syn_data using dplyr::pull() to get out all the values stored in the gc_score variable. How would you read this code?
Solution
Again, I’ve only printed out the first 10 values.
syn_data |> dplyr::pull(gc_score)
[1] NA NA NA NA 1.40 1.34 1.30 1.19 1.03 1.02
[ reached getOption("max.print") -- omitted 1201 entries ]
Your exact translation may vary, but one option is:
Take the syn_data dataset, and then pull out all the values in the gc_score variable.
If you’re wondering when to use $ and when to use dplyr::pull(), the answer depends on what you want to do! We’ll see some examples of both in just a moment.
Descriptives
Next up, we can start working with these values in the dataset. The base-R {stats} package contains a wide variety of very sensibly-named functions that calculate common descriptive statistics. These include:
mean() and median() (there is a function mode(), but it doesn’t do what we’d like it to here!)
min() for minimum value, max() for maximum value
range() for both minimum and maximum value in a single vector
sd() for standard deviation
A key feature of all of these functions is that, by default, they return NA if there are any NAs (missing values) present. (This is very sensible behaviour by default, but is frequently not the information we want when we use them.) So, they all have an argument, na.rm =, which determines whether NAs should be removed. By default this argument is set to FALSE (NAs should NOT be removed), but if you want to get the calculation ignoring any NAs, you can set this argument to TRUE instead.
Exercise
Calculate the mean, standard deviation, and median of the SCSQ global subscale, and the range of the grapheme-colour synaesthesia score.
Try using each subsetting method at least once.
Solution
We’ll start by using $ subsetting for the first bit, and pull() for the second. Not for any principled reason - feel free to try it either way.
mean(syn_data$scsq_global)
[1] 2.939389
sd(syn_data$scsq_global)
[1] 0.6011931
median(syn_data$scsq_global)
[1] 2.88
The gc_score variable has a large number of NAs. If we use the range() function without any other changes, we’ll just get NAs back as output. To remove NAs and work only with the non-missing values, we have to include the argument na.rm = TRUE.
As a quick check to get an individual number, this method is quite useful. However, you may have noticed that if we wanted this information for lots of variables, this would be repetitive, laborious, and prone to error. We’ve already seen how to use existing summary functions, but we will also look at creating custom summary tables in a future tutorial.
Visualisations
The final piece we will look at today will be base-R data visualisations in the {graphics} package. These built-in graphics functions are particularly helpful for quick spot checks during data cleaning and manipulation. For high-quality, fully customisable, professional data visualisations, we will use the {ggplot2} package, covered in depth in the next section of the course.
To get the idea, there are a few options for common plots:
hist() for histograms
boxplot() and barplot()
plot() for scatterplots
For more help and examples with base R graphics, try this quick guide.
Exercise
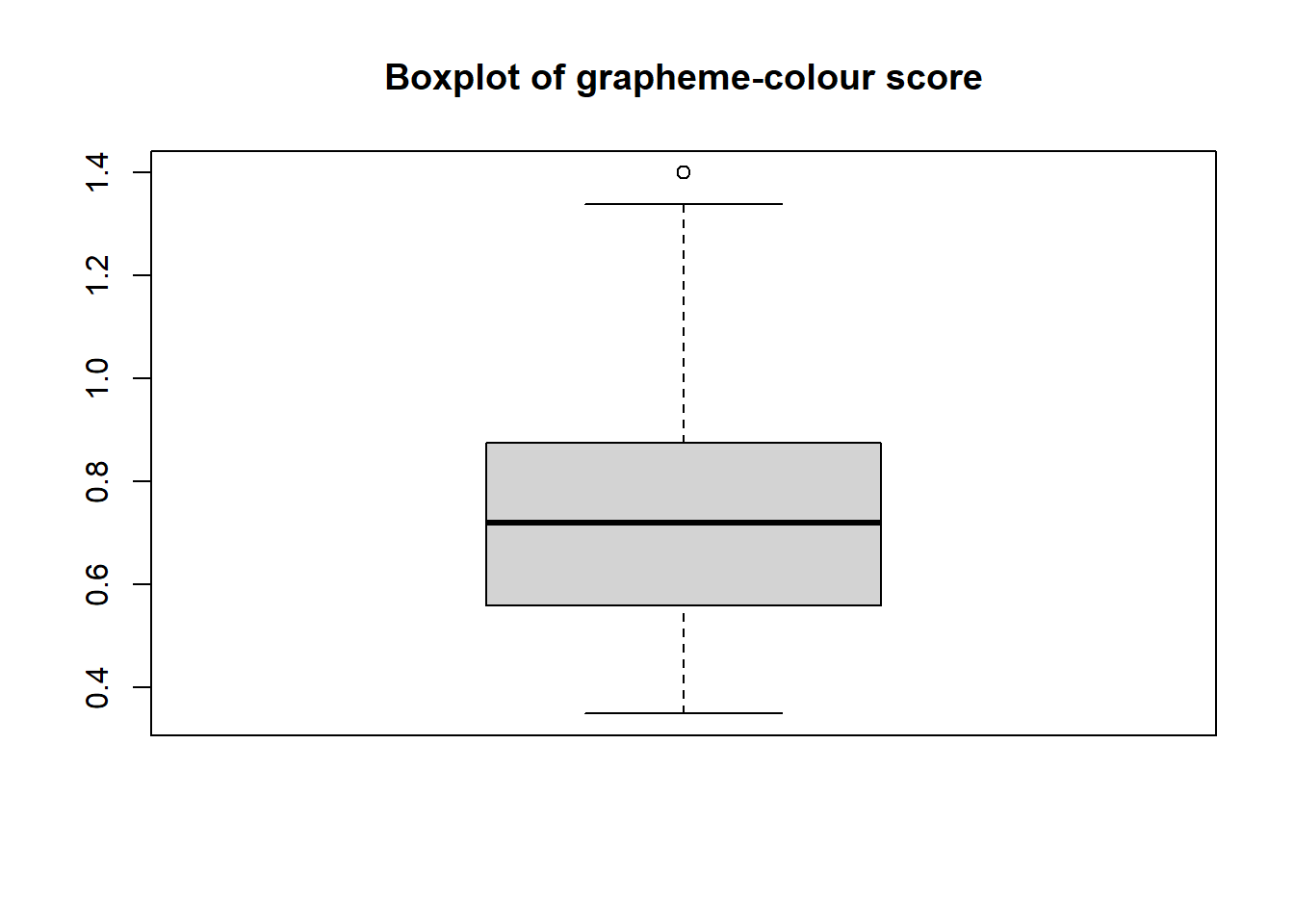
Try making a histogram and a boxplot, using any of the variables in the syn_data dataset. Try using $ and pull() once each.
Optionally, if you feel so inclined, use the help documentation to spruce up your plots a bit, such as changing the title and axis labels.
Solution
Histogram:
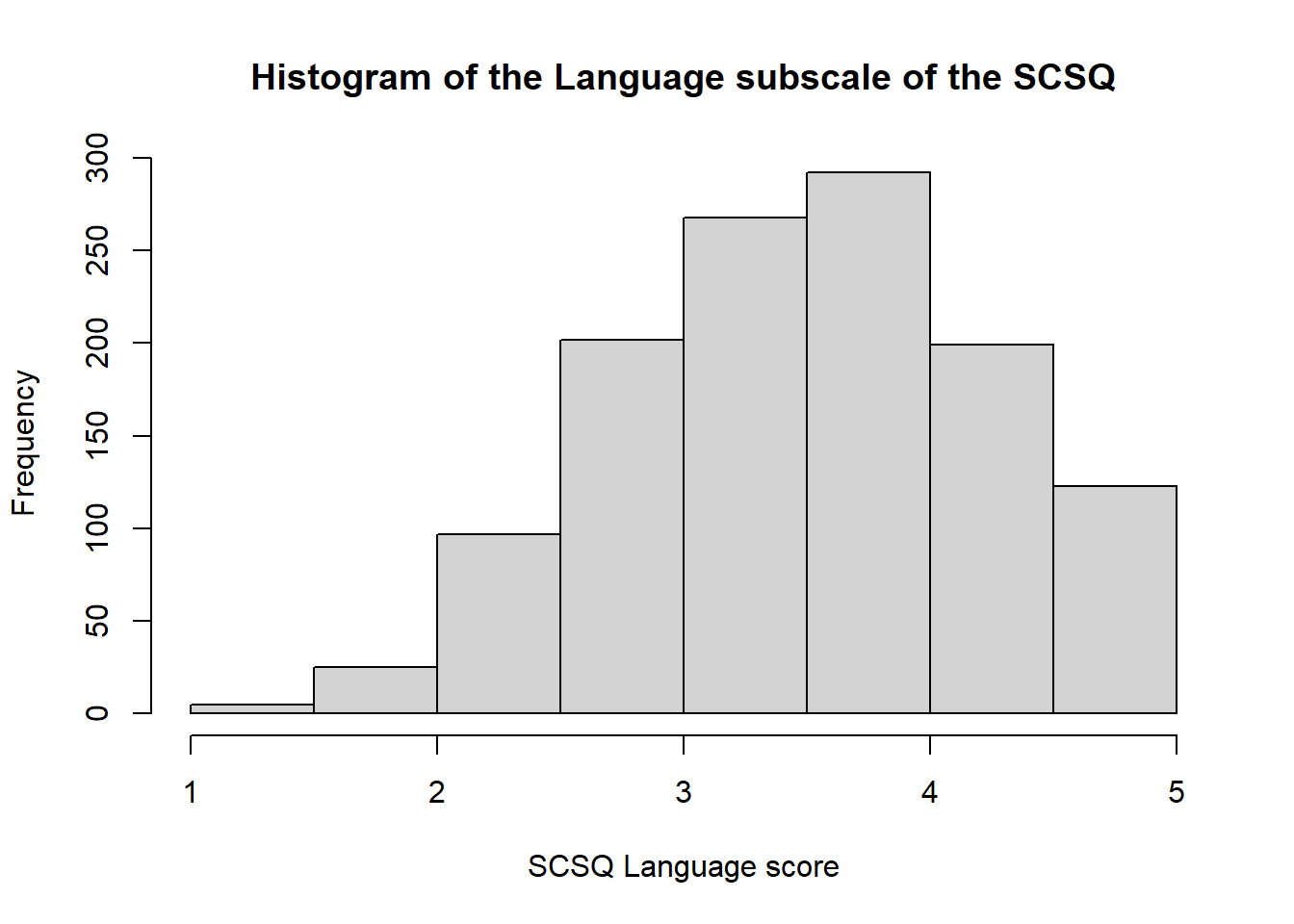
hist(syn_data$scsq_language)hist(syn_data$scsq_language,main ="Histogram of the Language subscale of the SCSQ",xlab ="SCSQ Language score")
CHALLENGE: Try making a barplot and a scatterplot.
For the barplot, make a visualisation of how many people are synaesthetes or not (regardless of synaesthesia type).
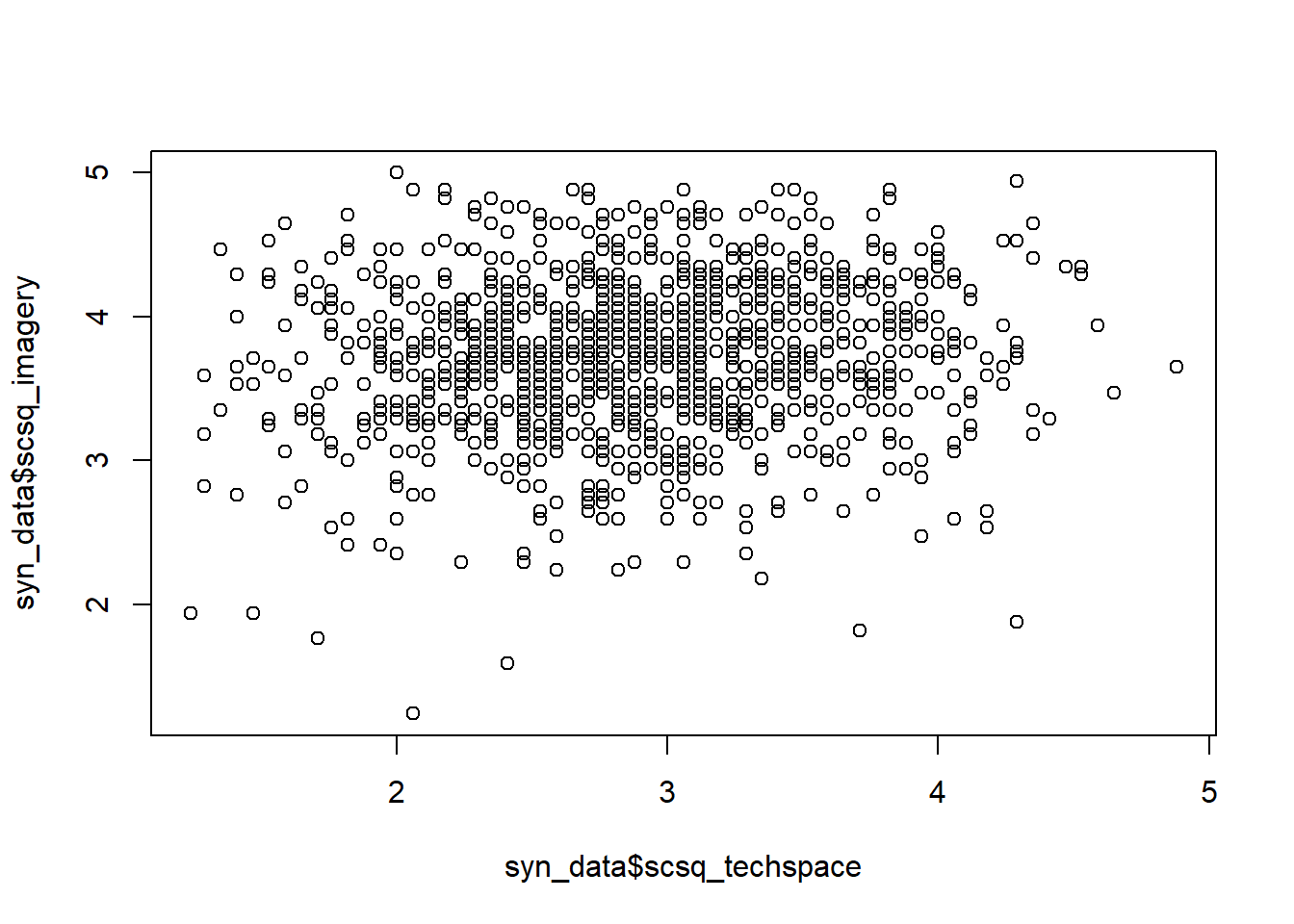
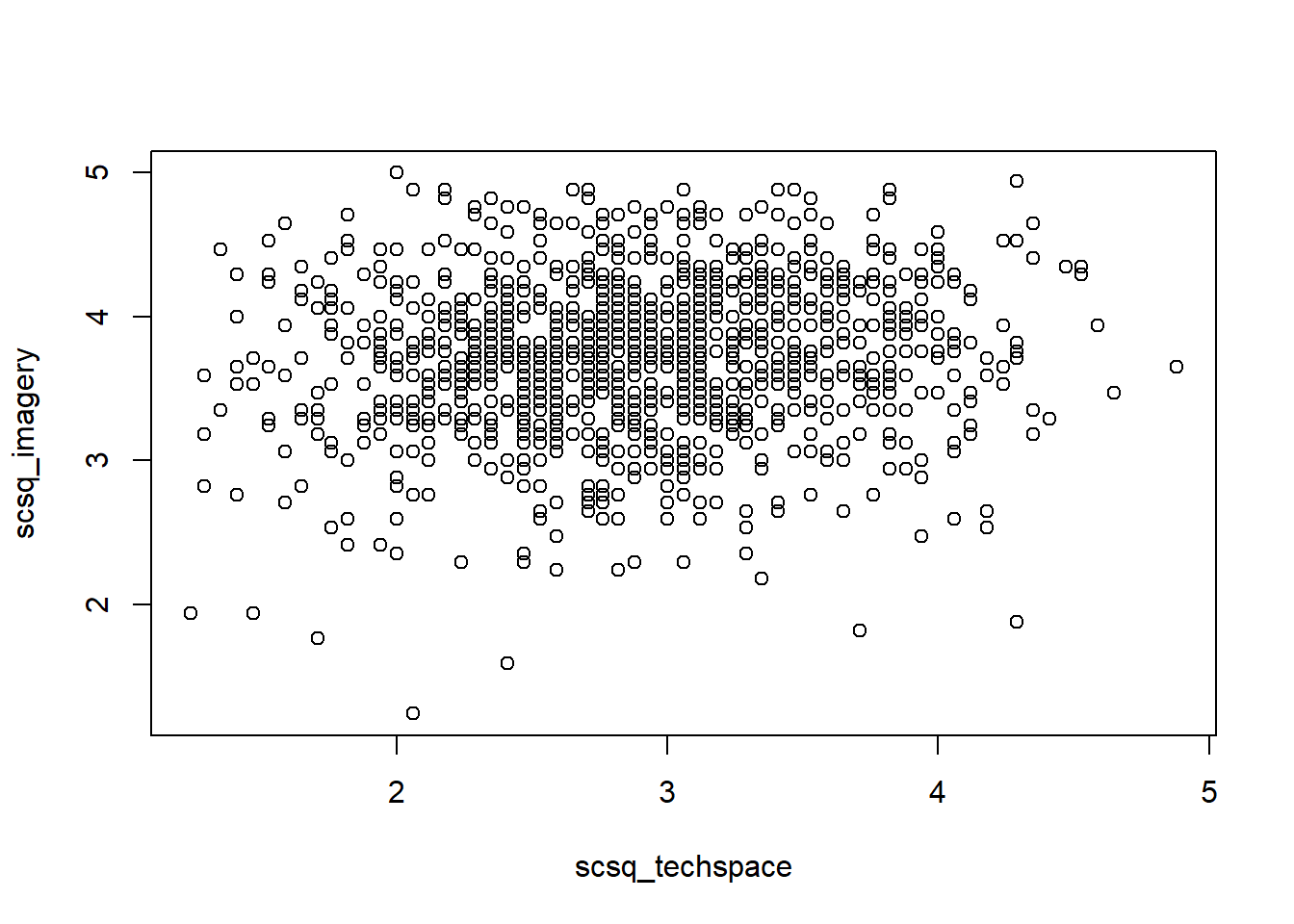
For the scatterplot, choose any two SCSQ measures.
Both of these require some creative problem-solving using the help documentation and the skills and functions covered in this tutorial.
Solution
The following solutions are options - if you found another way to make the same or similar plots, well done!
Barplots require two sets of values: a categorical one on the horizontal x axis and a continuous one on the vertical y axis. For something like frequency counts, then, we have to first do the counting, then pass those counts onto barplot(). Luckily we already know how to count categorical variables.
The help documentation is most helpful in the Examples section, where it shows actual examples of how the function works. There we can see an example of the formula method, y ~ x, which I’ve used below. Since we’re piping in the data to an argument that is not the first, I’ve used the placeholder in the data = _ argument to finish the command.
syn_data |> dplyr::count(syn) |>barplot( n ~ syn,data = _)
For the scatterplot, there are a couple of options. We can either supply x and y separately using $ subsetting, or use the same y ~ x formula we saw for barplots previously.
## Using subsettingplot(syn_data$scsq_techspace, syn_data$scsq_imagery)## Using a formulasyn_data |>plot(scsq_imagery ~ scsq_techspace, data = _)
Well Done!
That’s the end of this tutorial. Very well done on all your hard work!
Footnotes
You can read this notation as “the filter function from the dplyr package”, or just “dplyr filter”. As for how to pronounce “dplyr”, the official pronunciation is “dee-ply-er”, with “plier” like the tool for which it’s named. I have heard other people say “dipler”. Since code is always a bit tricky to read aloud, just go with whatever sounds good to you.↩︎
 shouting “Oh God no! Please no! NOOOOO”’)↩︎
Remember last week I mentioned that “first unnamed arguments” would be important? Here’s why! Look back on 01/02 IntRoductions if you’d like a refresher.↩︎
You can call this object anything you like; I use “px” as shorthand for “participant.”↩︎
This function always makes me think of one of those arcade claw machines reaching into the dataset to grab the values you want!↩︎